




For years, Node.js has not been the best choice to implement highly CPU intensive applications. This is mainly because Node.js is merely Javascript and JavaScript is single-threaded. Many alternative solutions were introduced to overcome this limitation to provide concurrency, but none were widely adopted because of performance limitations, additionally-introduced complexity, lack of adoption, instability or lack of documentation. As a solution to the problem, Node.js v10.5.0 introduced the experimental concept of Worker Threads via worker_threads module, which became a stable functionality since Node.js v12 LTS. In this article, I’m going to explain how to get the best out of worker threads and how they work in detail. If you are still not familiar with Node.js worker threads, I suggest you check out the official documentation of worker_threads first!
This article is the second article of my Advanced NodeJS Internals Series. You can find the other articles of the series below:
Post Series Roadmap
- Crossing the JS/C++ Boundary
- Deep Dive Into Worker Threads in Node.js (This article)
Please note that all the snippets referenced from the Node.js codebase are from the revision 921493e.
History of CPU Intensive Applications in Node.js
Before worker threads, there were multiple ways to perform CPU-intensive applications using Node.js. Some of those were,
- Using
child_processmodule and run CPU-intensive code in a child process. - Using cluster module to run multiple CPU-intensive operations in multiple processes.
- Using a third-party module such as Microsoft’s Napa.js.
Using worker threads for CPU intensive operations
Although worker_threads is an elegant solution for JavaScript’s concurrency problem, it does not introduce multi-threading language features to JavaScript itself. Instead, worker_threads implementation provides concurrency by allowing applications to use multiple isolated JavaScript workers where the communication between workers and the parent worker is provided by Node. Sounds confusing? 🤷♂️
In Node.js, each worker will have its own instance of V8 and Event Loop. However, unlike child processes, Workers can share memory.
At a later part in this post, I’ll explain in detail, how can they have their own V8 instance and Event Loop.
First of all, let’s have a brief look at how we can use worker threads. A naïve use case of worker threads might look like the following. Let’s call this script worker-simple.js.
In the above example, we pass a number to a separate worker to calculate its square. After calculating the square, the child worker sends the result back to the main worker thread. Although it sounds simple, it might seem a bit confusing if you are new to Node.js worker threads.
How do worker threads work?
JavaScript language does not have multi-threading features. Therefore, Node.js Worker Threads behave in a different way than traditional multi-threading in many other high-level languages.
In Node.js, a worker’s responsibility is to execute a piece of code (worker script) provided by the parent worker. The worker script will then run in isolation from other workers, with the ability to pass messages between it and the parent worker. The worker script can either be a separate file, or a script in textual format which can be evaled. In our example, we have provided __filename as the worker script because both of the parent and child worker codes are in the same script determined by isMainThread property.
Each worker is connected to its parent worker via a message channel. The child worker can write to the message channel using parentPort.postMessage function and the parent worker can write to the message channel by calling worker.postMessage() function on the worker instance. Have a look at the following diagram (Diagram 1).
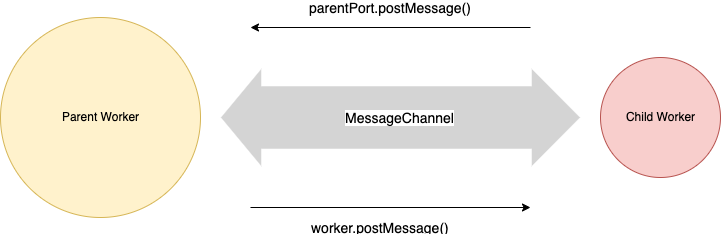 Diagram 1: Message Channel between the parent and the child workers
Diagram 1: Message Channel between the parent and the child workers
A Message Channel is a simple communication channel. It has two ends, which are called ‘ports’. In JavaScript/NodeJS terminology, two ends of a Message Channel are just called ‘port1' and ‘port2'. How thoughtful! 😁
How do Node.js workers run in parallel?
Now, the million-dollar question is, JavaScript does not provide concurrency straightaway, how can two Node.js workers run in parallel? The answer is V8 Isolates.
A V8 isolate is an independent instance of chrome V8 runtime which has its own JS heap and a microtask queue. This allows each Node.js worker to run its JavaScript code completely in isolation from other workers. The downside of this is that the workers cannot directly access each other's heaps directly.
Due to this, each worker will have its own copy of libuv event loop which is independent of other worker’s and the parent worker’s event loops.
Crossing the JS/C++ boundary
Instantiation of a new worker and providing communication across the parent JS script and worker JS script is set by the C++ worker implementation. At the time of this writing, this is implemented in worker.cc.
Worker implementation is exposed to userland JavaScript scripts using worker_threads module. This JS implementation is split into two scripts which I’d like to name as:
- Worker Initialisation script — Responsible for instantiating the worker instance and set-up initial parent-child worker communication to enable passing worker metadata from the parent to the child worker.
- Worker Execution script — Executes the user’s worker JS script with user-provided workerData and other metadata provided by the parent worker.
The following diagram (Diagram 2) will explain this in a much more clear way. Let’s go through what’s described by this diagram.
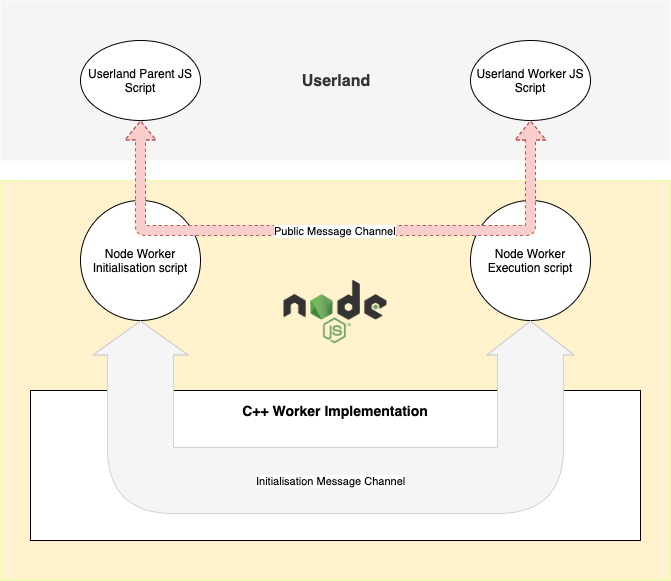
Based on the above, we can split the worker setup process into two stages. They are:
- Initialization of the worker
- Running the worker
Let’s have a look at what happens during each step.
Initialization Step
- Userland script creates a worker instance by using
worker_threadsmodule. - Node’s parent worker initialization script calls into C++ and creates an instance of an empty worker object. At this point, the created worker is nothing but a simple C++ object which is not yet started.
- When the C++ worker object is created, it generates a thread ID and assigns itself.
- An empty initialisation message channel is created (Let’s call it, IMC) by the parent worker when the worker object is created. This is shown in Diagram 2 as “Initialisation Message Channel”)
- A public JS message channel is created by the worker initialisation script (Let’s call it PMC). This is the message channel which is used by the userland JS in order to pass messages between the parent and the child worker using *.postMessage() functions. This is briefly described in Diagram 1, and can also be seen in red colour in Diagram 2.
- Node parent worker initialisation script calls into C++ and writes the initialisation metadata to the IMC which needs to be sent to the worker execution script.
What is this initialisation metadata? This is the data which the worker execution script needs to know to start the worker including the script name to be run as a worker, worker data, port2 of the PMC and some other information.
According to our example, the initialisation metadata is merely a message like:
Hey Worker Execution Script, Could you please run worker-simple.js with worker data {num: 5}? Also please pass port2 of the PMC to it so that the worker can read from and write to the PMC.
The following is a short snippet to show how initialisation metadata is written into the IMC.
In the above snippet, this[kPort], is the initialisation script’s end of the IMC. Even though the worker initialisation script writes to the IMC, the worker execution script cannot still access this data as it has not run yet.
Running Step
At this point, initialisation is complete. Then the worker initialisation script calls into C++ and starts the worker thread.
- A new v8 isolate is created and assigned to the worker. A v8 isolate is an independent instance of the v8 runtime. This makes the worker thread’s execution context isolated from the rest of the application code.
- libuv is initialized. This enables the worker thread to have its own event loop independent from the rest of the application.
- Worker execution script is executed, and the worker's event loop is started.
- Worker execution Script calls into C++ and reads initialisation metadata from the IMC.
- The Worker execution script executes the file (or code) to be run as a worker. In our case worker-simple.js.
See the following redacted snippet on how the worker execution script
Here’s the cool finding!
Did you notice in the above snippet that workerData and parentPort properties are set on require('worker_threads') object by the worker execution script??
This is why workerData and parentPort properties are only available inside the child worker thread’s code, but not in the parent worker’s code.
If you try to access those properties inside the parent worker’s code, they both will return null.
Getting the best out of worker threads
Now we understand how Node.js Worker Threads work. Understanding how they work indeed helps us to get the best performance using worker threads. When writing more complex applications than our worker-simple.js, we need to remember the following two major concerns with worker threads.
- Even though worker threads are lightweight than actual processes, spawning workers involve some serious work and can be expensive if done frequently.
- It’s not cost-effective to use worker threads to parallelise I/O operations because using Node.js native I/O mechanisms are way faster than starting up a worker thread from scratch just to do that.
To overcome the first concern, we need to implement “Worker Thread Pooling”.
Worker Thread Pooling
A pool of Node.js worker threads is a group of running worker threads which are available to be used for incoming tasks. When a new task comes in, it can be passed to an available worker via the parent-child message channel. Once the worker completes the task, it can pass the results back to the parent worker via the same message channel.
Once implemented properly, thread pooling can significantly improve the performance as it reduces the additional overhead of creating new threads. It also worthy to mention as creating a large number of threads is also not efficient as the number of parallel threads that can be run effectively is always limited by the hardware.
The following graph is a performance comparison of three Node.js servers which accept a string and returns a Bcrypt hash with 12 salt rounds. The three different servers are:
- Server with no multi-threading
- Server with multi-threading, but without any thread pooling
- Server with a thread pool of 4 threads
As it can be seen at first glance, using a thread pool has a significantly less cost as the workload increases.

However, at the time of this writing, thread pooling is not natively provided by Node.js out-of-the-box. Therefore, you might have to rely on third-party implementations or write your own worker pool.
In the below, I have included a reference implementation of a pool which I used for the above experiment. But it is only for the learning purposes and should NEVER be used in production.
I hope you now understand how worker threads work in-depth and can start experimenting and writing your CPU intensive applications with worker threads. If you have your own worker threads implementation or a library that you’d like to recommend, please feel free to comment.